

在 Reed-Solomon(RS)纠删码中,Vandermonde 矩阵(范德蒙德矩阵)是构造生成矩阵(Generator Matrix)的基础工具。以下以正式、结构化的方式,逐步说明其产生过程,特别是针对存储系统(如 HDFS EC)中常用的系统化(systematic)形式。
1. Vandermonde矩阵的基本定义
给定一个有限域 GF(q)(通常 q = 2^8 = 256 或 2^16),选择 n 个互不相同的元素 α₁, α₂, …, αₙ ∈ GF(q),称为评估点(evaluation points)。
Vandermonde 矩阵 V(尺寸 n × k)定义为:
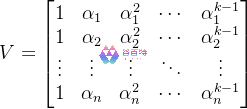
其核心性质:只要所有αᵢ互不相同,则任意 k 行(或 k 列)组成的子矩阵都是可逆的(行列式非零)。这正是 RS 码达到 MDS(最大距离可分)属性的数学基础。
2. 从Vandermonde矩阵到RS码生成矩阵的产生步骤
大多数实际系统(包括 HDFS EC、Jerasure、ISA-L、Backblaze 等)采用系统化 RS 码,即前 k 个码字符号等于原始 k 个数据符号(单位矩阵 I 出现在生成矩阵左侧)。
产生过程分为以下标准步骤:
步骤1:选择评估点序列
选取 n = k + m 个互不相同的元素作为α₁, …, αₙ。 常见选择(实际库中固定):
最简单:{0, 1, 2, …, n-1}(如果 0 包含在内)。
更常见(避免 0 带来的数值问题):{1, α, α², …, α^{n-1}},其中α是有限域的本原元素(primitive element)。
HDFS EC(基于 ISA-L 或 Java coder)通常使用预定义的固定序列(如从 1 开始的幂次,或 0 到 n-1 的整数表示),具体值在编码器初始化时硬编码,不对外暴露。
步骤2:构造原始Vandermonde矩阵G₀(n × k)
直接用上述 n 个评估点构建:
G₀(i,j) = α_i^{j} (行索引 i 从 1 到 n,列索引 j 从 0 到 k-1)
步骤3:实现系统化(Systematization)
为了让生成矩阵前 k 行成为单位矩阵 I,需要进行线性变换:
取 G₀的前 k 行组成子矩阵 V(即 Vandermonde 矩阵的前 k 行,尺寸 k × k,可逆)。
计算 V 的逆矩阵 V⁻¹。
最终系统化生成矩阵 G = G₀ × V⁻¹
结果形式:
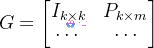
其中:
前 k 行是单位矩阵 I(原始数据直接输出)。
后 m 行 P 用于生成校验符号:parity = P × data。
所有运算都在有限域 GF(2^w) 内完成(加法 = 异或,乘法 = 有限域乘法表或对数表实现)。
3. 为什么必须这样产生(而非直接拼接I和某矩阵)
直接在单位矩阵下方拼接任意 Vandermonde 行会导致整体矩阵的任意 k 行不一定线性无关,从而破坏 MDS 属性(可能无法从任意 k 个符号恢复全部数据)。 通过 G = G₀ × V⁻¹ 这一步,保证了任意 k 行组成的子矩阵等价于某个 Vandermonde 子矩阵 × 可逆矩阵,因此仍然可逆,保留了最大纠删能力。
4. HDFS EC中的实际情况
HDFS 内置 RS 策略(如 RS-6-3、RS-3-2 等)使用固定、预计算的 Vandermonde 构造。
评估点序列在编码器(如 org.apache.hadoop.io.erasurecode.rawcoder 或 ISA-L native 库)中是硬编码的,通常为 {0,1,2,...,n-1} 或{1,2,...,n}的整数表示(在 GF(256)中映射为域元素)。
一旦 EC 策略确定,整个集群内所有使用该策略的文件都共享同一套固定的生成矩阵(及其逆矩阵,用于解码)。
用户无法自定义评估点;这属于实现层面的优化选择。
5. 小型示例RS(3,2)
场景假设:我们要保护 3 个数据块(d₀, d₁, d₂),生成 2 个校验块(p₀, p₁),最多能丢失任意 2 个块还能恢复。
步骤1:先选5个不同的“点”(评估点 α)
最简单起见,GF(256),我们选: α = [0, 1, 2, 3, 4] (实际系统中会选更合适的点,但原理一样)
步骤2:用这些点造原始Vandermonde矩阵(5行 × 3列)
每一行对应一个点αᵢ,每一列是αᵢ的 0 次方、1 次方、2 次方:
原始矩阵 G₀(还没系统化):
这就是最原始的 Vandermonde 矩阵。
步骤3:系统化
前 3 行变成单位矩阵 I
我们希望最终生成矩阵的前 3 行是:

这样,编码时前 3 个输出就直接等于原始数据 d₀, d₁, d₂(非常方便)。
怎么做到?用线性代数技巧:
取原始矩阵 G₀的前 3 行(对应α=0,1,2),记为 V(3×3 子矩阵):
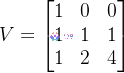
计算 V 的逆矩阵 V⁻¹(假设我们已经在有限域里算好了,这里只示意结果)。
最终生成矩阵 G = G₀ × V⁻¹
做完矩阵乘法后,G 的前 3 行自动变成单位矩阵,后 2 行变成我们真正用来算校验的系数。
结果示例(简化后的生成矩阵 G,可能的样子):
编码公式就变成:
块 0 = d₀
块 1 = d₁
块 2 = d₂
块 3 (p₀) = a·d₀ + b·d₁ + c·d₂
块 4 (p₁) = d·d₀ + e·d₁ + f·d₂
(a,b,c,d,e,f 是通过上面矩阵乘法算出来的固定系数)
步骤4:为什么用Vandermonde矩阵
想象你要用3 个方程解 3 个未知数(恢复丢失的数据)。 你需要保证:任意选 3 行(不管哪 3 行)组成的方程组都有唯一解。
Vandermonde 矩阵正好满足这个性质:
只要所有α不同,任意 k 行都是线性无关的(行列式≠0)。
所以无论丢失哪 2 个块(剩下任意 3 个),你都能列出可解的方程组 → 能恢复。
如果随便选系数(不用 Vandermonde),很可能某些 3 行会线性相关 → 某些情况下就解不出来(容错能力变差)。
生活类比(最浅显理解)
把 Vandermonde 想象成“5 个不同高度的测量点”:
你用一个二次多项式(最高 x²)去拟合 3 个数据点。
在 5 个不同高度测量这个多项式值 → 得到 5 个结果。
即使其中任意 2 个测量点坏掉,只要剩下 3 个,你总能唯一确定这个二次多项式 → 恢复所有原始值。
Vandermonde 矩阵就是保证“不同高度的测量点总是能唯一确定多项式”的数学工具。
6 总结
Vandermonde 矩阵的产生是先选定一组互异评估点 → 构建原始幂次矩阵 G₀ → 通过左乘其前 k 行子矩阵的逆来系统化。 在 HDFS EC 等生产系统中,这一过程是一次性、固定的,由编码器实现决定,用户仅选择 (k,m) 策略,即隐式决定了对应的 Vandermonde 构造。
7 问题
1)hdfs ec的Reed-Solomon生成矩阵是何时产生的?
在 HDFS Erasure Coding(EC)中,Reed-Solomon(RS)生成矩阵(Generator Matrix)的产生时机是固定的、一次性的,且发生在编码器(Codec)初始化阶段。在 RS 编码器实例被首次创建并初始化时一次性生成并缓存。
2)为何Reed-Solomon生成矩阵是一次性产生,而非每次写入?
RS(k,m) 的生成矩阵完全由以下因素决定:
k(数据单元数)
m(校验单元数)
使用的 Coder 实现(默认 RS、RS-LEGACY、ISA-L native 等)
Vandermonde 矩阵的评估点序列(HDFS 内置策略中是硬编码的固定值)
这些参数在整个集群生命周期内对于同一 EC 策略是不变的。
因此矩阵是常量,只需计算一次即可永久复用,避免重复的有限域矩阵求逆等昂贵运算。
3)HDFS EC的Reed-Solomon生成矩阵在每次java实例启动,或编码器重新初始化后,会保持不变吗?
Reed-Solomon 生成矩阵完全由以下固定参数决定:
数据单元数 k
校验单元数 m
使用的底层 Coder 实现(默认 RS、RS-LEGACY、ISA-L native 等)
评估点序列(HDFS 内置策略中为硬编码的固定值)
这些参数在整个集群生命周期内对于同一 EC 策略(如 RS-6-3-1024k)是不变的。因此,同一 Coder 类型 + 同一 (k,m) 的生成矩阵在数学上是常量,无需也不应因实例重启而改变。
4)ISA-L native级和纯java实现的 Reed-Solomon生成矩阵的数值会一样吗?
在 Hadoop HDFS Erasure Coding(EC)中,native 级别(ISA-L 实现)和纯 Java 实现(rs_java)的 Reed-Solomon 生成矩阵数值通常是一致的。
Hadoop 官方文档和源代码明确指出:
默认 RS codec(io.erasurecode.codec.rs)下的 native 实现(ISA-L)和纯 Java 实现(rs_java)是兼容的。
这意味着对于相同的 EC 策略(如 RS-6-3、RS-3-2 等),两种实现产生的编码结果(parity 块)必须相同,否则解码会失败或不兼容。
兼容性要求的核心是:生成矩阵(系数矩阵)必须相同,包括 Vandermonde 矩阵的评估点序列和系统化后的系数。
5)RS-3-2和RS-6-3生成矩阵是一致吗?
RS-3-2 和 RS-6-3 的 Reed-Solomon 生成矩阵(Generator Matrix)是不一致的,它们的系数数值完全不同。
6)Hadoop中Reed-Solomon编码器的实际实现位置?
Hadoop 的 RS(Reed-Solomon)原始编码 / 解码器(RawErasureCoder)主要位于以下包下:
主要实现类:
org.apache.hadoop.io.erasurecode.rawcoder.RSRawEncoder(纯 Java 实现中的 RS 编码器)
org.apache.hadoop.io.erasurecode.rawcoder.RSRawDecoder(对应的解码器)
org.apache.hadoop.io.erasurecode.rawcoder.NativeRSRawEncoder(基于 Intel ISA-L 的 native 实现)
org.apache.hadoop.io.erasurecode.rawcoder.RSLegacyRawEncoder(遗留的 RS 实现,源自 HDFS-RAID 项目)
评论区