

声明:本文是对 Addy Osmani 文章 Loop Engineering(2026 年 6 月
7 日发布)的独立解读与延展分析。文中核心概念(如"循环工程"六大组件框架、“理解债务”、"认知投降"等)属于原作者 Addy Osmani
的原创思想,本文通过重新组织结构、补充原创图解、加入个人分析视角进行二次创作。所有图解均为作者独立绘制。
Anthropic Claude Code 负责人 Boris Cherny 最近说了这样一句话:
“我不再直接提示 Claude 了。我有正在运行的循环来提示 Claude 并弄清楚该做什么。我的工作是编写循环。”
开发者工具先驱 Peter Steinberger 也表达过类似观点:
“你不应该再亲自提示编程代理了。你应该设计循环来提示你的代理。”
这不仅仅是一句口号。过去两年里,我们与 AI 编程代理的交互模式是这样的:你写提示 → AI 执行 → 你读结果 → 你再写提示。代理是工具,你全程掌控它,一轮接一轮。
但现在,一个新的范式正在浮现——循环工程(Loop Engineering)。你不再亲手驱动每一轮,而是构建一个小型系统,让它自己发现工作、分配任务、检查结果、记录进度、决定下一步。你不是在提示代理,你是在设计提示代理的系统。
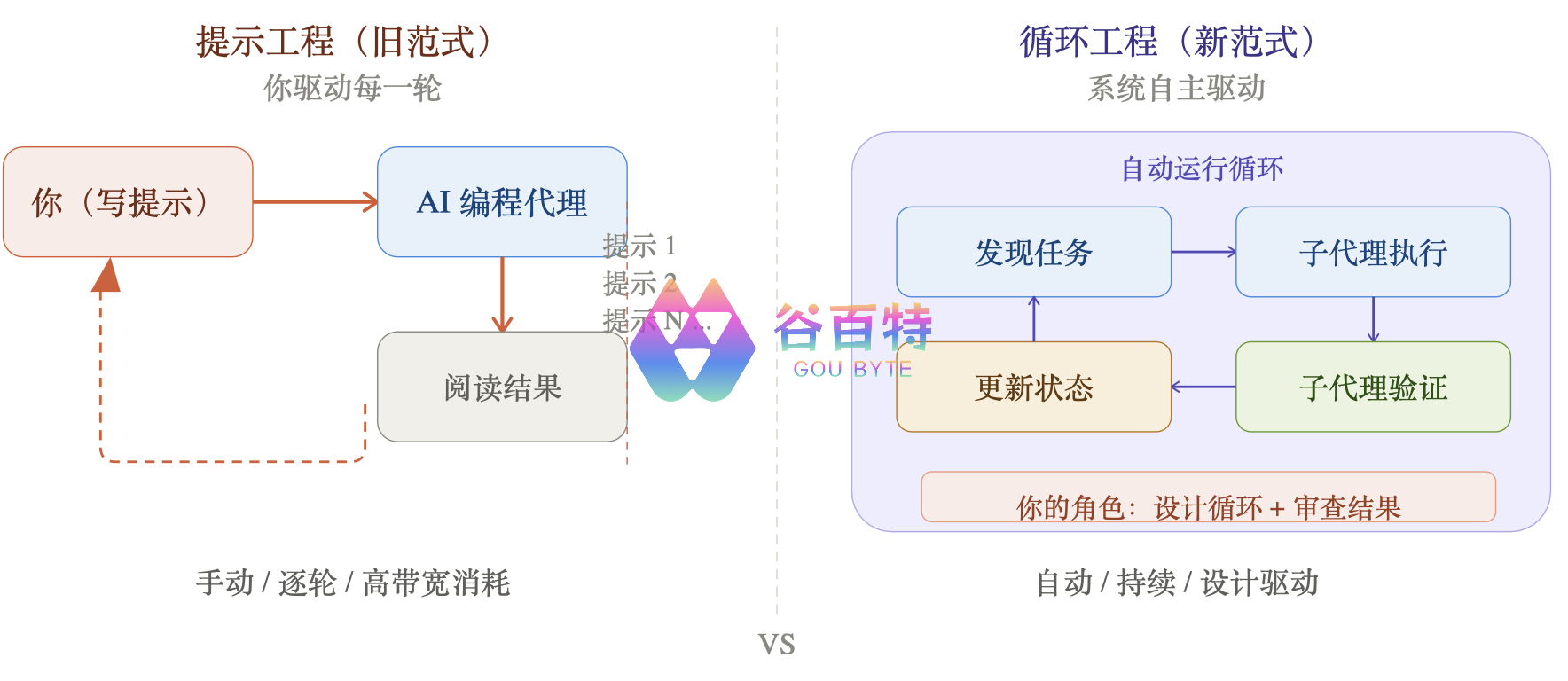
上图清晰地展示了两种范式的区别——
- 左侧旧范式:你作为中央枢纽,手动驱动每一轮交互,带宽消耗大
- 右侧新范式:系统自主循环运行,你的角色转变为"设计循环 + 审查结果"
循环需要什么?六大核心组件
Addy Osmani 提出了一个极简框架:"一个循环需要五个东西,再加一个地方记住东西"。这六个组件构成了循环工程的完整基础设施:
| 组件 | 在循环中的角色 | 如果缺失会怎样 |
|---|---|---|
| 自动化(Automations) | 定时触发,发现和分类任务 | 循环不会启动,一切需要手动 |
| 工作树(Worktrees) | 隔离并行功能,避免冲突 | 多个代理互相覆盖代码 |
| 技能(Skills) | 固化项目知识,每次运行读取 | 每次从零推导项目约定 |
| 插件/连接器(Plugins) | 连接 GitHub、Linear、Slack 等真实工具 | 循环只能告诉你该做什么,不能替你做 |
| 子代理(Sub-agents) | 实现与验证分离 | 写代码的人自己审查自己的代码 |
| 状态存储(State) | 跨会话记忆进度 | 每天重新开始,重复已完成的工作 |
下面这张架构图展示了组件之间的协作关系:
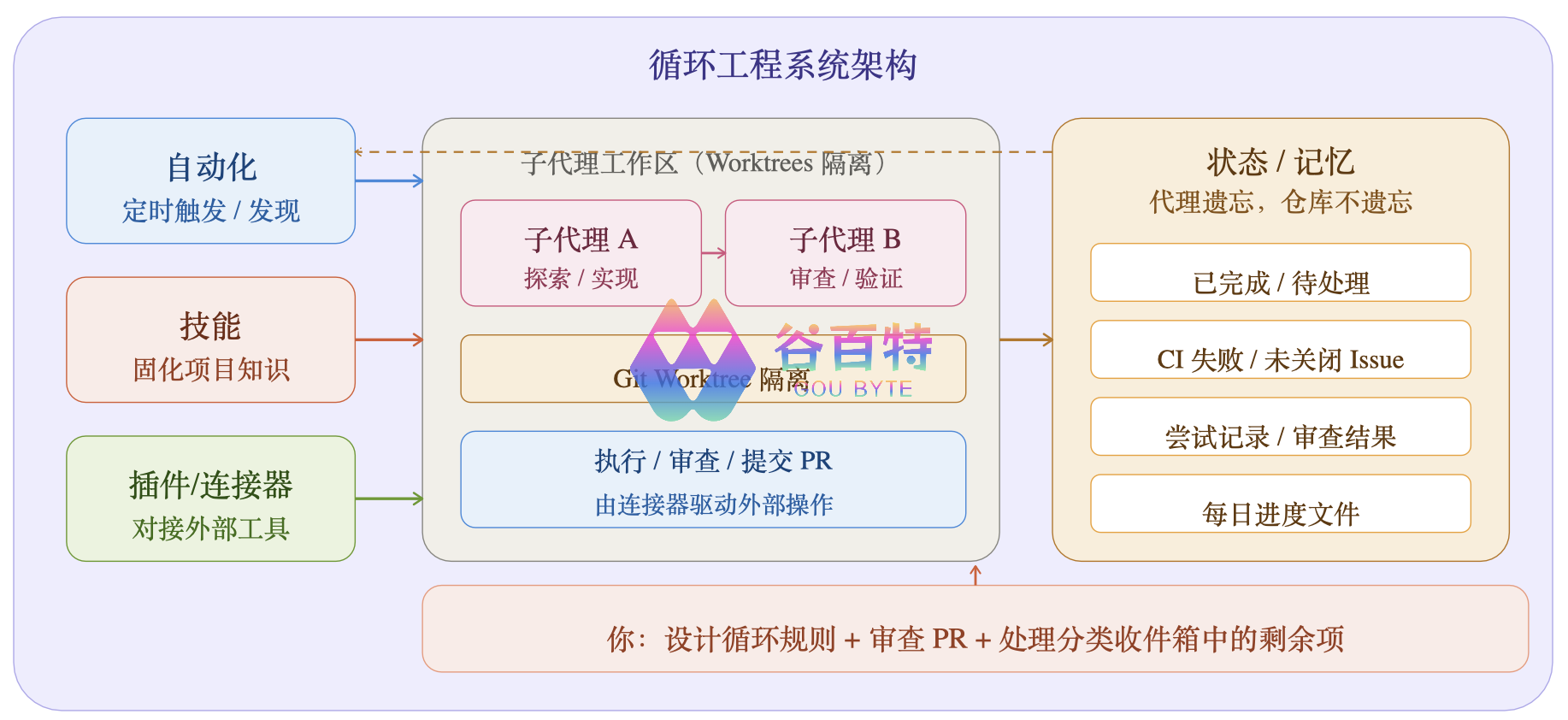
左侧三个「基础设施组件」为中央子代理提供支撑,右侧状态存储实现跨会话记忆。虚线箭头代表反馈闭环——状态文件中的信息会反哺给下一轮自动化触发,形成持续改进的飞轮。
两种关键的循环原语
自动化模块提供了两种核心运行模式:
/loop:按固定频率重新运行(如每天早上 6 点)/goal:持续运行直到你设定的条件为真,每轮运行后由独立的第三方小模型检查是否完成
/goal 的设计哲学很值得玩味——写代码的代理不负责给自己评分。这种"制衡机制"正是循环能在你不在场时仍然可信的关键。
"代理会遗忘,仓库不会"
关于状态存储,原文中有一句话让我印象深刻:
"The model forgets everything between runs so the memory has to be on disk and not in the context. The agent forgets, the repo doesn't."
代理每次会话都是"冷启动"的,会遗忘之前的一切。所以循环的进度、尝试记录、审查结果必须持久化到磁盘(Markdown 文件或 Linear 面板)。没有状态存储,循环就像一个每天醒来都失忆的人。
关于技能(Skills):消除"意图债务"
代理每次会话开始时会填补你意图中的空白,并做出自信的猜测——这被称为"意图债务"(Intent Debt)。技能的作用就是将意图显式编码:项目约定、构建步骤、"因为我们出过事故所以不这样做"——写一次,代理每次运行时读取。没有技能,循环每次从零推导项目;有了技能,它会不断累积经验。
一个完整循环的一天
让我们用一个真实场景来串联所有组件。以下是一个生产环境中循环的典型运行流程:

注意中间的并行阶段(06:10)——工作树 A 和工作树 B 同时运行:
- 工作树 A:子代理负责起草修复代码,读取技能文件遵循项目约定
- 工作树 B:子代理 B 独立审查代码,不信任子代理 A 的产出
这就是"实现与验证分离"的核心价值。两个代理在独立分支上工作,互不干扰。
到了早上 9 点,当你打开电脑时,循环已经完成了大部分工作。你的任务是:
- 审查已经开好的 PR
- 处理分类收件箱中循环无法自动完成的复杂事项
- 更新技能文件,让明天的循环更聪明
工具无关的抽象层
一个关键的洞察:循环的底层结构已经超越了单一工具的边界。无论是 OpenAI 的 Codex 还是 Anthropic 的 Claude Code,六大组件的映射几乎一致:
| 组件 | Codex(OpenAI) | Claude Code(Anthropic) |
|---|---|---|
| 自动化 | Automations 选项卡、/goal |
cron 定时、/loop、/goal、hooks |
| 工作树 | 内置每线程工作树 | git worktree、--worktree标志 |
| 技能 | Agent Skills(SKILL.md) |
Agent Skills(SKILL.md) |
| 插件 | Connectors(MCP)+ 插件分发 | MCP 服务器 + 插件 |
| 子代理 | TOML 定义在 .codex/agents/ |
定义在 .claude/agents/ |
| 状态 | Markdown 或 Linear | Markdown(AGENTS.md)或 Linear |
两者都使用 SKILL.md 和 MCP——为其中一个编写的技能和连接器,通常可以直接在另一个中使用。
循环解决不了的三个问题
循环改变了工作方式,但它不会删除你。Addy Osmani 在文中用了大量的篇幅提醒读者:随着循环变得更强,三个问题反而变得更加尖锐。
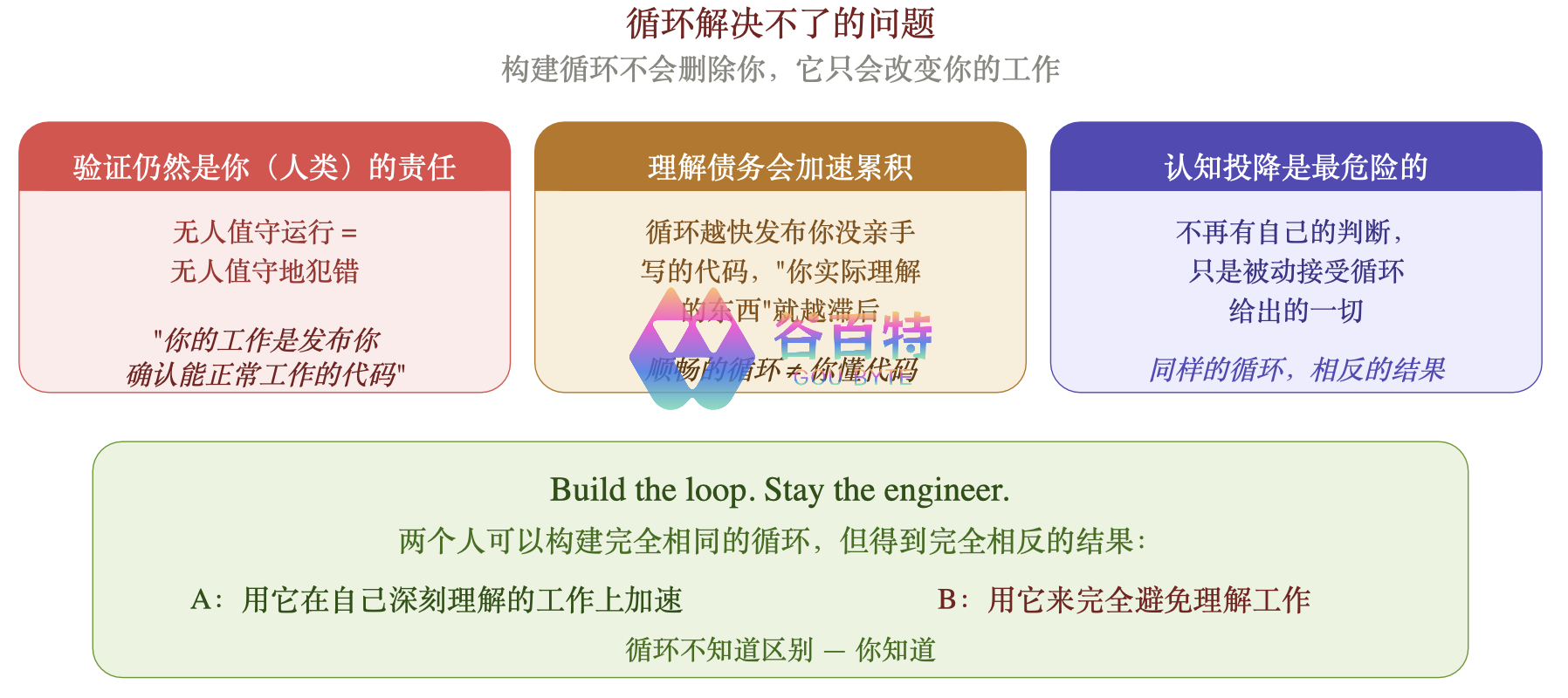
1. 验证仍然是你(人类)的责任
无人值守运行的循环也在无人值守地犯错。将验证子代理与制造子代理分离,正是为了让循环的"完成了"这句话更有意义——但即便如此,"完成"只是一个声明,不是证明。
"Your job is to ship code you confirmed works."
2. 理解债务(Comprehension Debt)
循环越快地发布你没有亲手写的代码,"代码库里存在的东西"和"你实际理解的东西"之间的差距就越大。一个顺畅的循环只会让理解债务增长得更快——除非你主动阅读循环产出的每一行代码。
3. 认知投降(Cognitive Surrender)——最危险的陷阱
当循环自动运行,很容易就不再有自己的判断,只是接受它给出的一切。Addy 将这称为认知投降。
设计循环,当你带着判断去做时是解药;当你用它来避免思考时是催化剂——同样的行动,相反的结果。
这一点尤其值得警惕。两个人可以构建完全相同的循环,但得到完全相反的结果:A 用它在深刻理解的工作上加速,B 用它来完全避免理解工作。循环不知道区别——你知道。
我的思考
在我看来,"循环工程"这篇文章之所以重要,不在于它提出了什么全新的技术——六大组件大多已经在现有产品中存在。它的价值在于提供了一个认知框架,让你从"提示技巧"的思维层面,升级到"系统设计"的思维层面。
几个值得深思的点:
第一,杠杆点在转移。 一年前要构建类似的循环,你需要写一堆 bash 脚本并持续维护。现在这些组件直接内置于产品中。门槛降低意味着更多人会开始尝试,但也会更多人陷入"认知投降"。
第二,工程师的角色不会消失,但会升级。 循环设计比提示工程更难,而不是更容易。你需要同时具备系统思维(设计循环)、领域知识(编写技能)和工程判断力(审查结果)。这不是"按下开始按钮等结果"的工作。
第三,Token 成本是隐形门槛。 文中提到的子代理模式——每轮都有独立的探索、实现、验证代理——意味着 Token 消耗可能是传统模式的数倍。这对个人开发者和小团队来说是一个现实约束。
第四,直接提示仍然有效。 不要把循环工程教条化。有些场景下,直接提示代理反而是最高效的方式。循环工程是工具箱中的一件新工具,不是要替换所有旧工具。
总结
最后,用 Addy Osmani 的那句话作为收尾:
Build the loop. Stay the engineer.
构建循环,但仍然做个工程师。不是像只负责按下"开始"按钮的人,而是像一个打算继续深刻理解代码的人。代理会遗忘,仓库不会——你设计的循环、编码的技能、写入的状态文件,这些才是跨越时间和会话持久存在的东西。
循环工程不是终点,它是一个工程师在 AI 时代的新起点。
评论区