

HDFS 短路本地读取系列(二):你以为的「本地读」和真正的「本地读」—getLegacy vs getBlockReaderLocal 的本质差异
导语:在 HDFS 的读取路径中,
BlockReaderFactory.build()是客户端选择读取策略的总入口。在这个四级降级链路中,第二级和第三级分别由getLegacyBlockReaderLocal()和getBlockReaderLocal()接管。一个基于文件路径直接打开(HDFS-2246),一个基于 Unix Domain Socket 文件描述符传递(HDFS-347)。本文将深入 Hadoop 3.x源码,彻底解读这两个方法的内部机制、调用链路与设计哲学。
一、背景:为什么需要短路本地读取?
传统 HDFS 读取路径中,即使客户端与 DataNode 同机,数据也要经过:
磁盘 → Page Cache → DataNode 用户态 Buffer → TCP Send Buffer → TCP Recv Buffer → 客户端用户态 Buffer
这是 3 次 CPU 拷贝 的马拉松。当 Spark 扫描百亿行 Parquet、HBase 承载百万 QPS 时,这 3 次拷贝会被放大为整个系统的性能。
短路本地读取(Short-Circuit Local Read) 的核心思想:客户端与 DataNode 同机时,让客户端直接读取本地块文件,绕过 DataNode 的 TCP 协议栈。
Hadoop 实现了两套短路读取机制,分别由 getLegacyBlockReaderLocal() 和 getBlockReaderLocal() 触发。
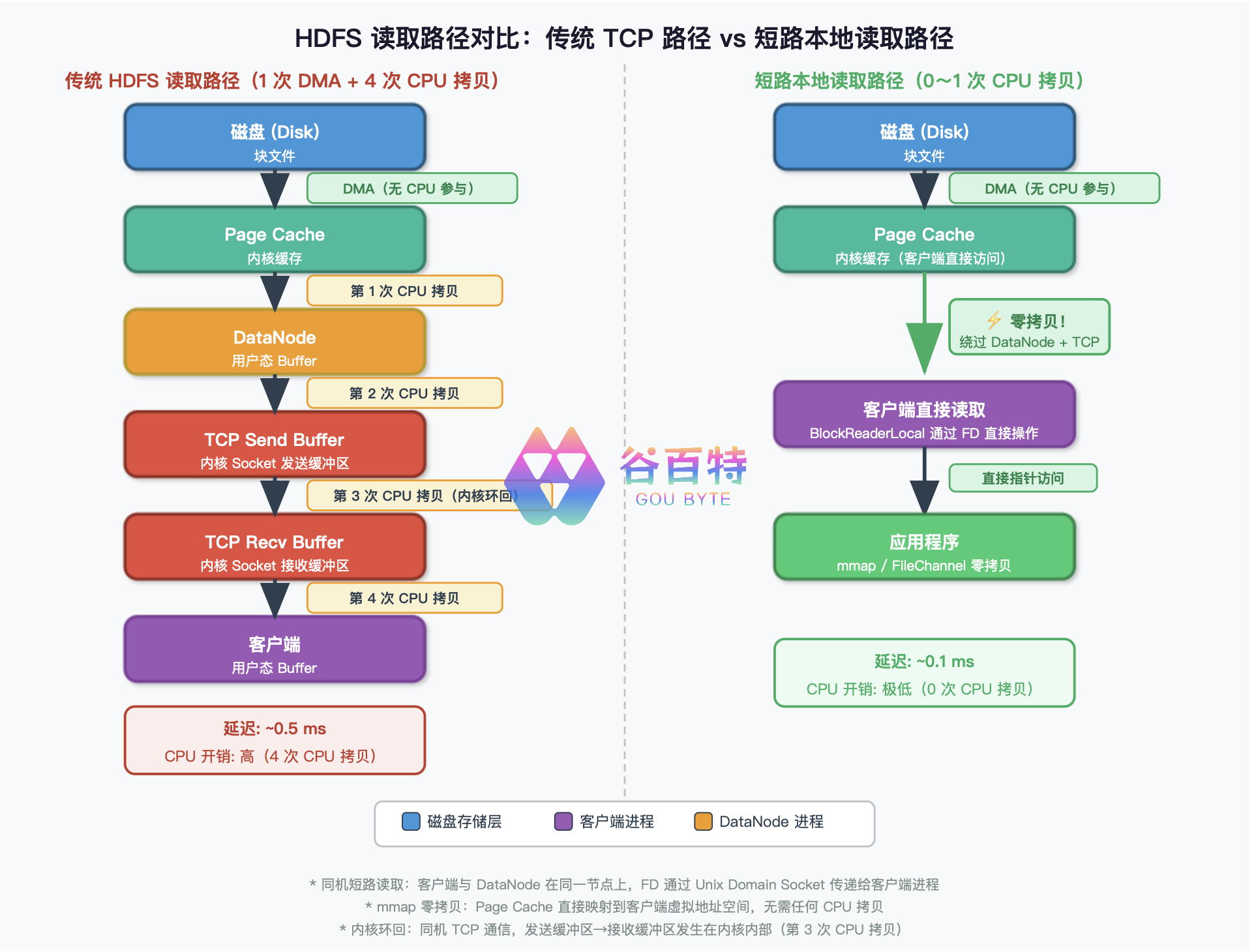
1.1 内核环回 vs 普通 TCP:第 3 次 CPU 拷贝的特殊性
传统路径中的 "第 3 次 CPU 拷贝"标注为"内核环回",这里详细解释它和普通跨机器 TCP 的区别。
内核环回(Kernel Loopback)指的是同机 TCP 通信时,数据走 127.0.0.1 回环接口。很多人误以为 127.0.0.1 就是"短路"——但实际上它仍然要完整遍历 TCP 协议栈:
DataNode write()
→ tcp_sendmsg() // 分段、拷贝到 sk_buff
→ tcp_transmit_skb() // 构造 TCP 头、计算校验和(纯 CPU 算!)
→ ip_queue_xmit() // IP 层路由
→ loopback_xmit() // 发现目标在本地,直接丢入接收队列
→ netif_rx() // 触发软中断(NET_RX_SOFTIRQ)
→ tcp_v4_rcv() // TCP 入站处理
→ tcp_rcv_established() // 重组、ACK、窗口
→ sock_def_readable() // 通知接收 socket
Client read()
| 维度 | 普通 TCP(跨机器) | 内核环回(同机 127.0.0.1) |
|---|---|---|
| 数据路径 | 内核 → NIC 驱动 → 网线 → 对端 NIC → 内核 | 全程在内核内部兜一圈 |
| DMA 次数 | 2 次(发送 NIC + 接收 NIC 各读/写内存) | 0 次(根本不出网卡) |
| TCP 协议栈 | 完整走一遍 | 完整走一遍(一行代码不少) |
| 校验和 | 硬件 offload 到网卡(TCP Segmentation Offload) | CPU 自己算 |
| 数据是否拷贝 | 通过 sk_buff 跨机器传输 | 同机器时 skb_clone() 共享数据页,不一定 literal memcpy() |
| 主要瓶颈 | 网卡带宽(10G/25G/100G) | 内核 TCP 栈 CPU 处理能力 |
关键认知:内核环回未必执行字面意义上的
memcpy()数据拷贝(现代内核通过skb_clone()共享数据页),但 TCP 协议栈处理本身(分段、校验和、ACK、窗口管理)就是巨大的 CPU 开销。图中标注的"第 3 次 CPU 拷贝(内核环回)",指的是数据走完整 TCP 栈所消耗的 CPU 代价——这才是短路读取真正要绕过的。
而短路读取的优势恰恰在于:Client 根本不走 socket,拿到 FD 后直接 pread() / mmap() 操作块文件——连 TCP 栈的影子都没有。这就是为什么延迟能从 ~0.5ms 降到 ~0.1ms。
二、总入口:BlockReaderFactory.build() 的四级降级链路
// BlockReaderFactory.java — build() 方法(简化)
public BlockReader build() throws IOException {
// 第0级:外部插件(ReplicaAccessorBuilder)
BlockReader reader = tryToCreateExternalBlockReader();
if (reader != null) return reader;
final ShortCircuitConf scConf = conf.getShortCircuitConf();
try {
if (scConf.isShortCircuitLocalReads() && allowShortCircuitLocalReads) {
if (clientContext.getUseLegacyBlockReaderLocal()) {
// 第一级短路:Legacy 路径(本文主角之一)
reader = getLegacyBlockReaderLocal();
if (reader != null) return reader;
} else {
// 第二级短路:新式 fd 传递路径(本文主角之二)
reader = getBlockReaderLocal();
if (reader != null) return reader;
}
}
if (scConf.isDomainSocketDataTraffic()) {
// 第三级:Domain Socket 数据流(仍走 DataNode,但无 TCP)
reader = getRemoteBlockReaderFromDomain();
if (reader != null) return reader;
}
} catch (IOException e) { /* 降级 */ }
// 最终兜底:TCP 远程读取
return getRemoteBlockReaderFromTcp();
}
关键配置开关:
| 配置项 | 默认值 | 作用 |
|---|---|---|
dfs.client.read.shortcircuit | false | 是否启用短路读取 |
dfs.client.use.legacy.blockreader.local | false | true → 走 getLegacyBlockReaderLocal() |
dfs.domain.socket.path | 空 | Domain Socket 路径模板(如 /var/run/hadoop-hdfs/dn._PORT) |
BlockReaderFactory.build() 四级降级链路
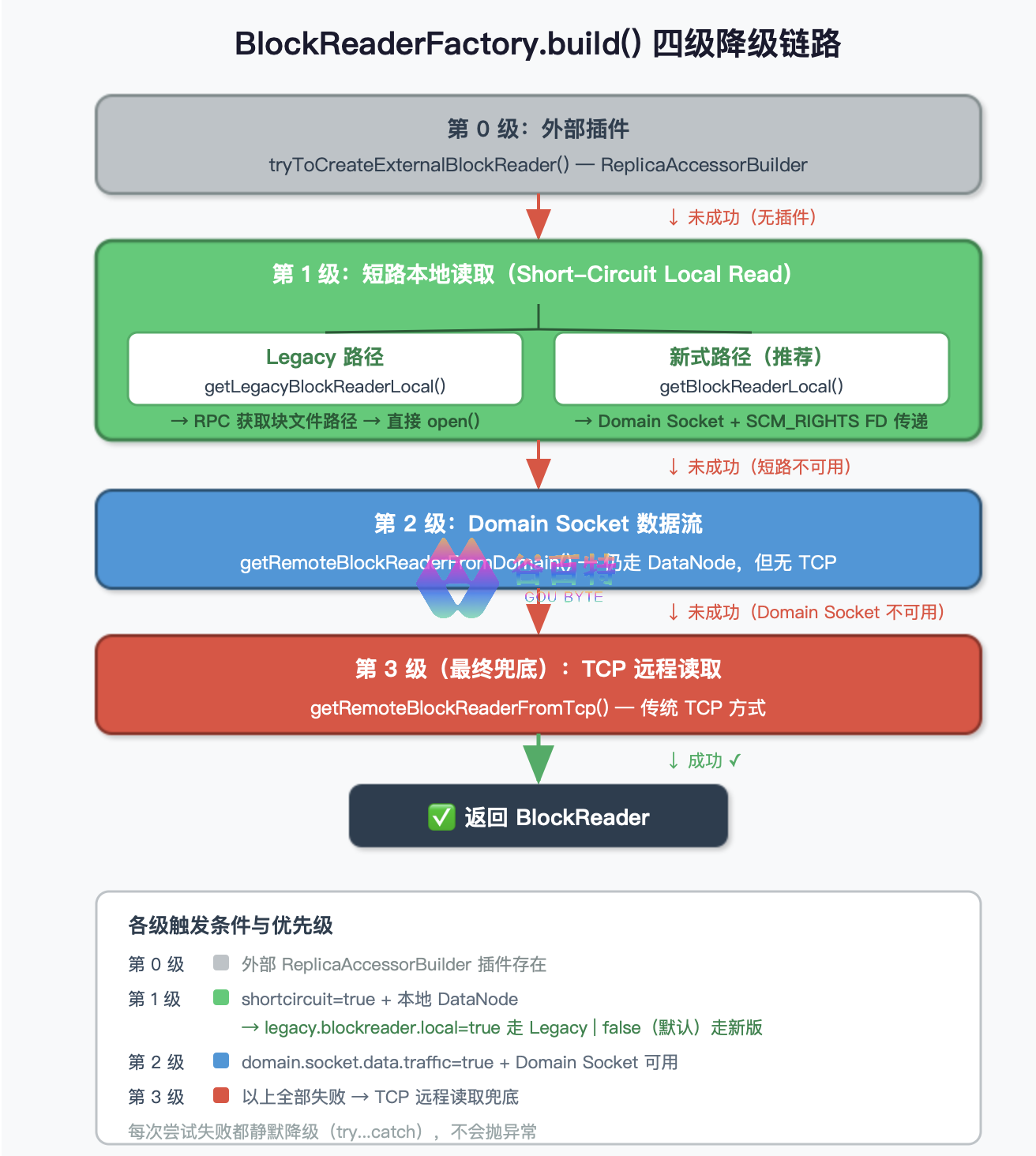
各级降级触发条件对照表:
| 降级级别 | 方法 | 触发条件 | 配置开关 |
|---|---|---|---|
| 第0级 | tryToCreateExternalBlockReader() | 存在外部 ReplicaAccessorBuilder 插件 | — |
| 第1级(Legacy) | getLegacyBlockReaderLocal() | dfs.client.read.shortcircuit=true 且 dfs.client.use.legacy.blockreader.local=true | dfs.client.use.legacy.blockreader.local |
| 第1级(新版) | getBlockReaderLocal() | dfs.client.read.shortcircuit=true 且 dfs.client.use.legacy.blockreader.local=false(默认) | dfs.domain.socket.path |
| 第2级 | getRemoteBlockReaderFromDomain() | dfs.domain.socket.data.traffic=true 且 Domain Socket 可用 | dfs.domain.socket.data.traffic |
| 第3级(兜底) | getRemoteBlockReaderFromTcp() | 以上全部失败 | — |
设计哲学:每次尝试失败都静默降级(
try...catch),不会抛异常,直到找到可用的读取方式或最终走到 TCP 兜底。
三、getLegacyBlockReaderLocal深度解读
3.1 方法签名与调用时机
// BlockReaderFactory.java — getLegacyBlockReaderLocal()
private BlockReader getLegacyBlockReaderLocal() throws IOException
触发条件(必须全部满足):
dfs.client.read.shortcircuit = trueclientContext.getUseLegacyBlockReaderLocal() = true- 目标 DataNode 地址是本地地址(
DFSUtilClient.isLocalAddress()) clientContext.getDisableLegacyBlockReaderLocal() = false(未被上次失败禁用)
3.2 核心流程源码解读
private BlockReader getLegacyBlockReaderLocal() throws IOException {
// 【守卫条件1】目标必须为本机
if (!DFSUtilClient.isLocalAddress(inetSocketAddress)) {
return null;
}
// 【守卫条件2】未被上次失败禁用
if (clientContext.getDisableLegacyBlockReaderLocal()) {
return null;
}
try {
// 【核心】通过 RPC 获取块文件路径,然后直接打开
return BlockReaderLocalLegacy.newBlockReader(conf,
userGroupInformation, configuration, fileName, block, token,
datanode, startOffset, length, storageType);
} catch (RemoteException re) {
ioe = re.unwrapRemoteException(
InvalidToken.class, AccessControlException.class);
}
// 【失败处理】权限异常说明用户不在白名单,禁用 Legacy 路径
if ((!(ioe instanceof AccessControlException)) && isSecurityException(ioe)) {
throw ioe; // 非权限异常,直接抛出(阻止降级)
}
LOG.warn("Disabling legacy local reads.", ioe);
clientContext.setDisableLegacyBlockReaderLocal(); // 禁用
return null;
}
3.3 BlockReaderLocalLegacy.newBlockReader的 RPC 交互
// BlockReaderLocalLegacy.java — newBlockReader() 核心片段
static BlockReaderLocalLegacy newBlockReader(...) throws IOException {
// 【步骤1】从本地缓存获取块路径(LRU,最多 10000 条)
LocalDatanodeInfo localDatanodeInfo =
getLocalDatanodeInfo(node.getIpcPort());
BlockLocalPathInfo pathinfo = localDatanodeInfo.getBlockLocalPathInfo(blk);
if (pathinfo == null) {
// 【步骤2】缓存未命中,发起 RPC 调用
// 调用 DataNode 的 ClientDatanodeProtocol.getBlockLocalPathInfo()
pathinfo = getBlockPathInfo(userGroupInformation, blk, node,
configuration, conf.getSocketTimeout(), token,
conf.isConnectToDnViaHostname(), storageType);
}
// 【步骤3】直接打开本地文件(这是"短路"的本质)
File blkfile = new File(pathinfo.getBlockPath());
dataIn = new FileInputStream(blkfile); // 直接 open()
if (!skipChecksumCheck) {
File metafile = new File(pathinfo.getMetaPath());
checksumIn = new FileInputStream(metafile);
// 解析 checksum 头
final DataChecksum checksum = BlockMetadataHeader.readDataChecksum(...);
}
return new BlockReaderLocalLegacy(scConf, file, blk,
startOffset, checksum, verifyChecksum, dataIn, ..., checksumIn);
}
调用链路图:
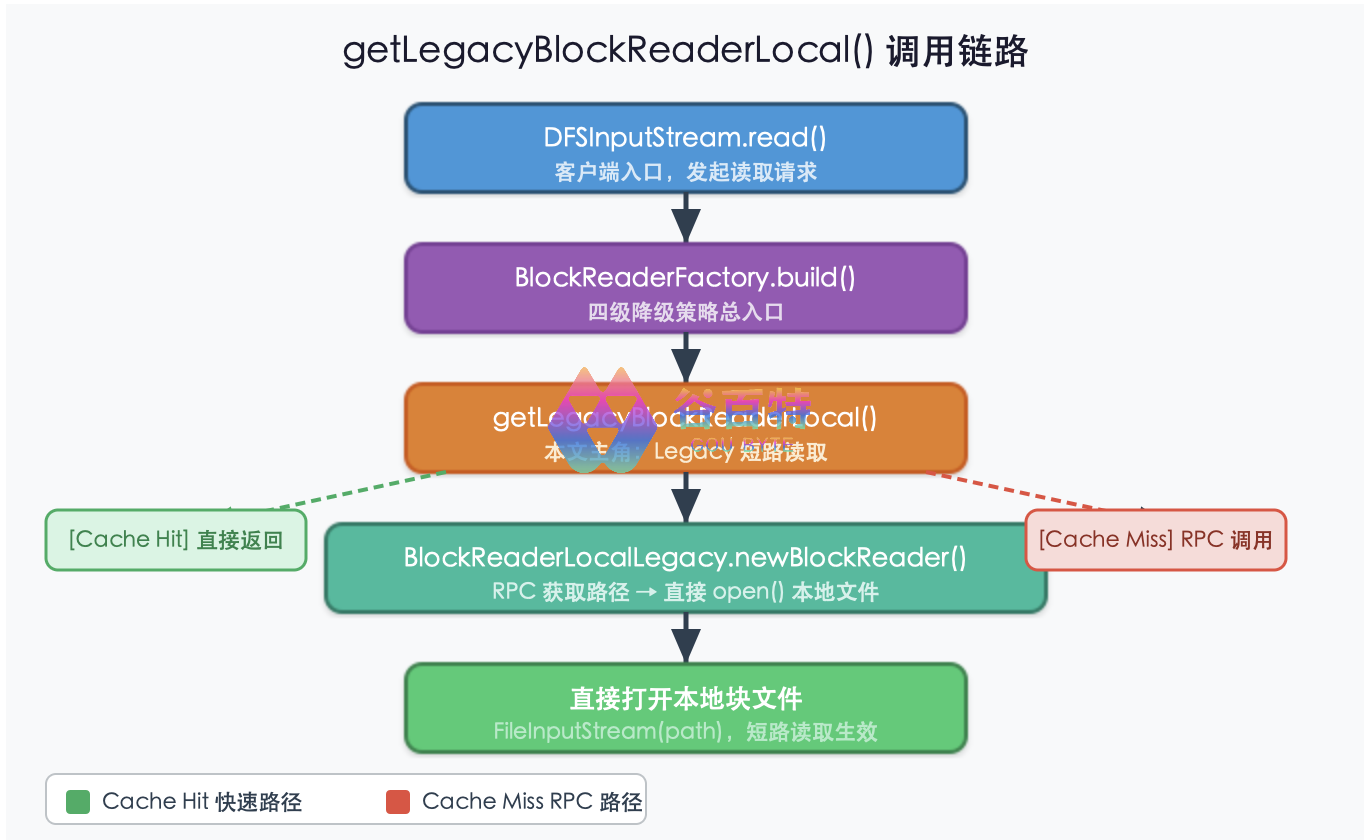
3.4 Legacy 路径的致命缺陷
- 权限问题:客户端需要直接读取 DataNode 数据目录的权限,通常需要将用户加入
dfs.block.local-path-access.user白名单,运维复杂。 - 安全问题:绕过 DataNode 直接读文件,DataNode 无法感知读取行为,也无法做节流控制。
- 缓存一致性:
LocalDatanodeInfo的 LRU 缓存在 DataNode 删除块后可能返回过期路径。
四、getBlockReaderLocal深度解读
4.1 方法签名与架构革新
// BlockReaderFactory.java — getBlockReaderLocal()
private BlockReader getBlockReaderLocal() throws IOException
对应 JIRA HDFS-347,核心是:通过 Unix Domain Socket 让 DataNode 把块文件的 FileDescriptor 传递给客户端。
这样客户端不需要直接访问数据目录的权限——DataNode 作为文件所有者打开 FD,然后通过内核级 SCM_RIGHTS 机制把 FD "发送" 给客户端。
4.2 核心流程源码解读
private BlockReader getBlockReaderLocal() throws IOException {
// 【步骤1】获取 Domain Socket 路径状态(带缓存)
if (pathInfo == null) {
pathInfo = clientContext.getDomainSocketFactory()
.getPathInfo(inetSocketAddress, conf.getShortCircuitConf());
}
// 【步骤2】检查路径是否可用
if (!pathInfo.getPathState().getUsableForShortCircuit()) {
return null;
}
// 【步骤3】从 ShortCircuitCache 获取或创建 ShortCircuitReplica
// (这是整个流程的灵魂)
ShortCircuitCache cache = clientContext.getShortCircuitCache();
ExtendedBlockId key = new ExtendedBlockId(
block.getBlockId(), block.getBlockPoolId());
// 【关键】fetchOrCreate() 是线程安全的 Fetch-Or-Create 模式
// 如果缓存中没有,会回调 this.createShortCircuitReplicaInfo()
// (this 实现了 ShortCircuitReplicaCreator 接口)
ShortCircuitReplicaInfo info = cache.fetchOrCreate(key, this);
if (info.getInvalidTokenException() != null) {
throw info.getInvalidTokenException();
}
if (info.getReplica() == null) {
return null; // 创建失败,返回 null 触发降级
}
// 【步骤4】使用 Builder 模式构造 BlockReaderLocal
return new BlockReaderLocal.Builder(conf.getShortCircuitConf())
.setFilename(fileName)
.setBlock(block)
.setStartOffset(startOffset)
.setShortCircuitReplica(info.getReplica()) // 注入 replica(含 data/meta fd)
.setVerifyChecksum(verifyChecksum)
.setCachingStrategy(cachingStrategy)
.setStorageType(storageType)
.build();
}
4.3 ShortCircuitCache.fetchOrCreate的并发艺术
这是整个短路读取中最精妙的设计之一:多线程请求同一 Block 时,只创建一个 ShortCircuitReplica,其余线程等待。
// ShortCircuitCache.java — fetchOrCreate()
public ShortCircuitReplicaInfo fetchOrCreate(ExtendedBlockId key,
ShortCircuitReplicaCreator creator) {
lock.lock();
try {
// 【快路径】缓存命中
Waitable<ShortCircuitReplicaInfo> waitable = replicaInfoMap.get(key);
if (waitable != null) {
info = fetch(key, waitable); // 等待或直接获取
if (info != null) return info;
}
// 【慢路径】缓存未命中:放入 Waitable,让其他线程等待
newWaitable = new Waitable<>(lock.newCondition());
replicaInfoMap.put(key, newWaitable);
} finally { lock.unlock(); }
// 【释放锁后】回调 creator.createShortCircuitReplicaInfo()
// 即 BlockReaderFactory.createShortCircuitReplicaInfo()
return create(key, creator, newWaitable);
}
Waitable 的作用是:多个线程可以同时 await() 同一个 Waitable,当创建线程调用 provide() 时,所有等待线程被唤醒并获得同一个 ShortCircuitReplicaInfo。
4.4 createShortCircuitReplicaInfo FD 传递的真正发生地
当缓存未命中时,ShortCircuitCache.create() 会调用 BlockReaderFactory.createShortCircuitReplicaInfo():
// BlockReaderFactory.java — createShortCircuitReplicaInfo()
@Override
public ShortCircuitReplicaInfo createShortCircuitReplicaInfo() {
// 【步骤1】获取或创建 Domain Socket 连接
DomainPeer peer = nextDomainPeer();
// 【步骤2】在共享内存中分配 slot(与 DataNode 同步状态)
ShortCircuitReplica.ShareMemorySlot slot = cache.allocShmSlot(...);
// 【步骤3】向 DataNode 发送短路读取请求
// 底层:Sender.requestShortCircuitFds()
requestShortCircuitFds(peer, slot, ...);
// 【步骤4】接收 DataNode 通过 SCM_RIGHTS 传递的 FD
// 底层:DomainSocket.recvFileInputStreams()
FileInputStream[] fis = peer.getDomainSocket().recvFileInputStreams(...);
// 【步骤5】封装为 ShortCircuitReplica
ShortCircuitReplica replica = new ShortCircuitReplica(
key, fis[0], fis[1], slot, ...); // fis[0]=data, fis[1]=meta
return new ShortCircuitReplicaInfo(replica);
}
4.5 DataNode侧 SCM_RIGHTS FD 传递的内核之旅
DataNode 的 DataXceiver.requestShortCircuitFds() 处理客户端请求:
// DataXceiver.java — requestShortCircuitFds()(DataNode 侧)
public void requestShortCircuitFds(...) throws IOException {
// 【步骤1】权限校验(验证 Block Token)
checkAccess(...);
// 【步骤2】在共享内存中注册 slot
datanode.getShortCircuitRegistry().registerSlot(...);
// 【步骤3】打开块文件(DataNode 有权限,因为它是文件 owner)
FileInputStream[] fis = datanode.requestShortCircuitFdsForRead(blk, token, maxVersion);
// 【步骤4】通过 SCM_RIGHTS 发送 FD
// 内核处理:为客户端进程分配新 FD,指向同一个 struct file
DomainSocket sock = peer.getDomainSocket();
sock.sendFileDescriptors(
new FileDescriptor[]{fis[0].getFD(), fis[1].getFD()},
buf, 0, buf.length);
}
SCM_RIGHTS 内核机制(简述):
- 发送方调用
sendmsg(),将 FD 放入辅助数据(cmsg_type = SCM_RIGHTS) - 内核在接收方进程的文件描述符表中分配新条目,指向发送方 FD 对应的同一个
struct file - 接收方拿到的新 FD 与发送方 FD 值不同,但指向同一文件偏移和状态
FD 传递全流程(SCM_RIGHTS 机制)
下面用图展示 getBlockReaderLocal() 完整调用链,从客户端发起请求到拿到 FD 的全过程:
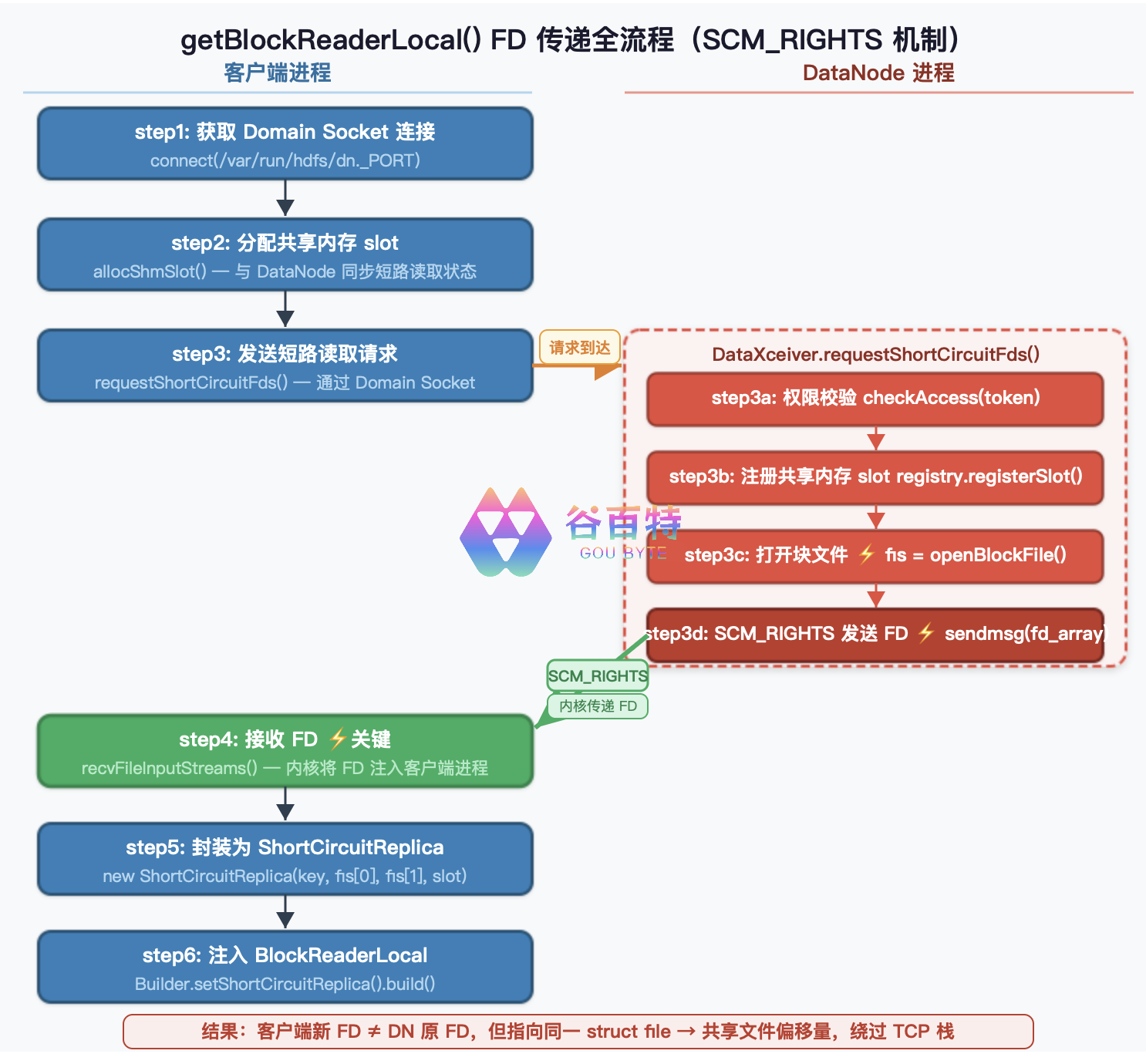
SCM_RIGHTS 内核机制简述:
| 步骤 | 发送方(DataNode) | 接收方(客户端) | 内核动作 |
|---|---|---|---|
| 1 | 调用 sendmsg(),FD 放入辅助数据 cmsg_type=SCM_RIGHTS | — | 识别 SCM_RIGHTS,找到 struct file |
| 2 | — | 调用 recvmsg() 接收 | 在接收方 FD 表中分配新条目,指向同一 struct file;返回新 FD 值(与发送方 FD 值不同) |
| 3 | — | 拿到 new FileInputStream(fd) | 后续 IO 直接操作同一文件偏移量 |
结果:客户端拿到的新 FD,和 DataNode 打开时的 FD 值不同,但指向同一文件描述符结构,共享文件偏移量和状态。
4.6 Unix Domain Socket 深度解析
上文反复提到 "Domain Socket",它到底是什么?和 TCP 环回有什么本质区别?
.sock文件在里面扮演什么角色?本节彻底讲清楚。
4.6.1 什么是 Domain Socket?
Unix Domain Socket(UDS) 是同机进程间通信(IPC)机制,数据只在内核内存中传递,不绕网卡,不走 TCP 协议栈。
| 维度 | TCP Socket(127.0.0.1) | Unix Domain Socket |
|---|---|---|
| 地址族 | AF_INET / AF_INET6 | AF_UNIX / AF_LOCAL |
| 寻址方式 | IP:Port | 文件系统路径(如 /var/run/hdfs/dn.sock) |
| 内核协议栈 | 完整 TCP/IP 栈(校验和、分段、ACK、拥塞控制) | 直接内核内存拷贝,无协议处理 |
| SCM_RIGHTS | ❌ 不支持 | ✅ 支持 FD 传递(这才是关键!) |
| 延迟 | ~0.05ms(协议栈开销) | ~0.005ms(纯内存搬运) |
| 安全模型 | IP 层面的访问控制 | 文件系统权限(0600)+ SO_PEERCRED 获取对端 UID |
4.6.2 .sock 文件的本质
/var/run/hdfs/dn.sock 不存储数据,它只做「门牌号」——让客户端通过文件系统路径找到服务端绑定的内核 struct socket 对象。
bind() 时内核做了什么?
DataNode 调用 bind("/var/run/hdfs/dn.sock"):
VFS 层:
→ 在路径上创建一个 inode
→ inode->i_mode = S_IFSOCK (socket 类型,不是普通文件!)
→ inode->i_fop = &socket_file_ops
内核内存:
→ 分配 struct socket + struct sock(AF_UNIX 协议族)
→ 服务端 fd 指向这个 struct socket
→ 把路径字符串和 struct socket 的对应关系记录到 Unix socket 哈希表
ls -l 输出:
srwx------ 1 hdfs hdfs ... /var/run/hdfs/dn.sock
↑ s 开头 = socket 文件类型
connect() 时内核做了什么?
客户端 connect("/var/run/hdfs/dn.sock"):
1. VFS 解析路径 → 找到 S_IFSOCK 类型的 inode
2. 通过 inode 找到 DN 绑定的 struct socket
3. 分配客户端自己的 struct socket
4. 内核将两端的 struct socket 配对:
→ 服务端 struct unix_sock->peer 指向客户端
→ 客户端 struct unix_sock->peer 指向服务端
→ 两端 sk_receive_queue 互相关联
结果:
客户端 fd → struct socket ←→ struct socket ← DN accept fd
↑ ↑
完全在内核内存中,不走网卡
一句话:
.sock文件是一个特殊的 inode(S_IFSOCK),内核通过它找到服务端绑定的struct socket。connect()的本质是让客户端的struct socket和服务端的struct socket配对,之后的通信直接在内核内存里完成。
4.6.3 谁做服务端?为什么?
DataNode 是服务端(bind + listen + accept),客户端是连接方(connect)。
正确的方向(HDFS 实际实现):
DataNode 启动:
├─ socket() → bind(/var/run/hdfs/dn.sock) → listen()
└─ accept() 阻塞等待
客户端发起短路读取:
├─ step1: connect(/var/run/hdfs/dn.sock) ← 主动连接 DN
├─ step2: allocShmSlot() ← 分配共享内存
├─ step3: sendmsg() 发送读取请求(普通数据)
└─ DN 收到请求后:
├─ checkAccess(token) ← 权限校验
├─ openBlockFile() ← 打开块文件,拿到 FD
└─ sendmsg(SCM_RIGHTS) ← 把 FD 发回客户端
为什么必须是 DN 做服务端?安全原因:
假设客户端做服务端(不可行):
→ DN 需要 connect() 到客户端的 socket
→ 客户端怎么告诉 DN "我的 socket 路径在哪"?
→ 任意进程都可以伪装成客户端...
正确设计(DN 做服务端):
→ /var/run/hdfs/dn.sock 固定路径,权限 0600
→ 客户端 connect() 时,DN 通过 SO_PEERCRED 获取客户端 UID
→ 结合 block token 校验,确保只有合法客户端能拿到 FD
4.6.4 全双工 & SCM_RIGHTS 双向
UDS 一旦建立,是全双工的:
UDS 连接建立后:
客户端 ←─────── 全双工 ──────→ DataNode
(同一条连接,双向同时可用)
客户端可以:sendmsg(SCM_RIGHTS) → DN 收
DN 也可以:sendmsg(SCM_RIGHTS) → 客户端收
SCM_RIGHTS 没有方向限制——只要在已连接的 socket 上调用 sendmsg() 即可。HDFS 实际只用了 DN → 客户端 这个方向(把块文件 FD 发给客户端),但反向在技术上完全可行。
4.6.5 SCM_RIGHTS 是系统调用
SCM_RIGHTS 本身不是系统调用,而是一个常量标志位。但通过 UDS 传递 SCM_RIGHTS 的整个动作,必须经过 sendmsg() / recvmsg() 这一对系统调用完成:
应用层:
sendmsg(sockfd, &msg, 0) ← 一次系统调用,从用户态陷入内核态
│
│ msg.msg_control 包含:
│ struct cmsghdr {
│ cmsg_type = SCM_RIGHTS; ← 常量标志,告诉内核"我要传 FD"
│ cmsg_data = {block_fd}; ← 要传递的 FD 值
│ }
│
▼ 内核态
__sys_sendmsg() → ___sys_sendmsg()
└─ scm_send()
└─ case SCM_RIGHTS:
scm_fp_copy(cmsg_data)
1. fget(fd) → 获取 struct file
2. 在接收方 FD 表中分配新条目,指向同一 struct file
3. 新 FD 值写回接收方的 cmsg_data
HDFS 短路读取中,这一步是关键路径——一次
sendmsg()+ 一次recvmsg(),FD 从 DataNode 进程传递到客户端进程,没有数据拷贝,但确实走了两次系统调用。
五、BlockReaderLocal 的读取路径:两种 I/O 模式
5.1 read() 方法的双分支
// BlockReaderLocal.java — read(ByteBuffer buf)
@Override
public synchronized int read(ByteBuffer buf) throws IOException {
boolean canSkipChecksum = createNoChecksumContext();
try {
if (canSkipChecksum && zeroReadaheadRequested) {
// 【路径 A】直接操作 FileChannel,无 bounce buffer
nRead = readWithoutBounceBuffer(buf);
} else {
// 【路径 B,默认】通过 bounce buffer 预读 + 可选 checksum 验证
nRead = readWithBounceBuffer(buf, canSkipChecksum);
}
return nRead;
} finally {
if (canSkipChecksum) releaseNoChecksumContext();
}
}
5.2 两个分支的触发条件(源码真相)
先说结论:readWithoutBounceBuffer() 在生产环境中几乎不会触发。
// BlockReaderLocal 构造函数(源码第 257-265 行)
int maxReadaheadChunks = (bytesPerChecksum == 0) ? 0 :
((Math.min(builder.bufferSize, builder.maxReadahead) +
bytesPerChecksum - 1) / bytesPerChecksum);
if (maxReadaheadChunks == 0) {
this.zeroReadaheadRequested = true; // ← 唯一触发条件
maxReadaheadChunks = 1;
} else {
this.zeroReadaheadRequested = false; // ← 正常 checksum 类型,永远 false
}
| 变量 | 含义 | 何时为 true |
|---|---|---|
zeroReadaheadRequested | 是否禁用预读(走直接读取) | 仅 bytesPerChecksum == 0 时(checksum 类型为 NULL) |
canSkipChecksum | 是否可以跳过 checksum 验证 | verifyChecksum=false 或 addNoChecksumAnchor() 成功 |
bytesPerChecksum == 0 意味着什么?
→ dfs.checksum.type=NULL,写入的块完全没有校验和
→ 这是一个几乎没人用的配置(数据损坏无法检测)
→ 所以 readWithoutBounceBuffer() 在生产中基本是死代码
那 dfs.client.read.shortcircuit.skip.checksum=true 有什么用?
// Builder 构造函数(第 89 行)
this.verifyChecksum = !conf.isSkipShortCircuitChecksums();
// ↑ dfs.client.read.shortcircuit.skip.checksum
设为 true 后:
verifyChecksum = falsecreateNoChecksumContext()返回true- 但
zeroReadaheadRequested仍为false - 结果:走
readWithBounceBuffer(),只是跳过了 checksum 验证,并没有零拷贝
5.3 readWithBounceBuffer():默认路径(2 次 CPU 拷贝)
重要澄清:readWithBounceBuffer ≠ 零拷贝。 名字里的 "bounce" 已经揭示了真相——数据需要先"弹"到一个中间缓冲区,再"弹"到用户目标缓冲区。
5.3.1 bounce buffer 在哪里?
// BlockReaderLocal.java 第 68 行
private static final DirectBufferPool bufferPool = new DirectBufferPool();
// 第 224 行
private ByteBuffer dataBuf; // ← 这就是 bounce buffer
// 第 284-286 行:懒初始化
private synchronized void createDataBufIfNeeded() {
if (dataBuf == null) {
dataBuf = bufferPool.getBuffer(
maxAllocatedChunks * bytesPerChecksum);
}
}
// DirectBufferPool.java — 底层是 allocateDirect
public ByteBuffer getBuffer(int size) {
// ...先从池里尝试复用...
return ByteBuffer.allocateDirect(size); // ← Direct ByteBuffer!
}
dataBuf 是 DirectByteBuffer,位于用户进程的堆外 native 内存,不在内核空间:
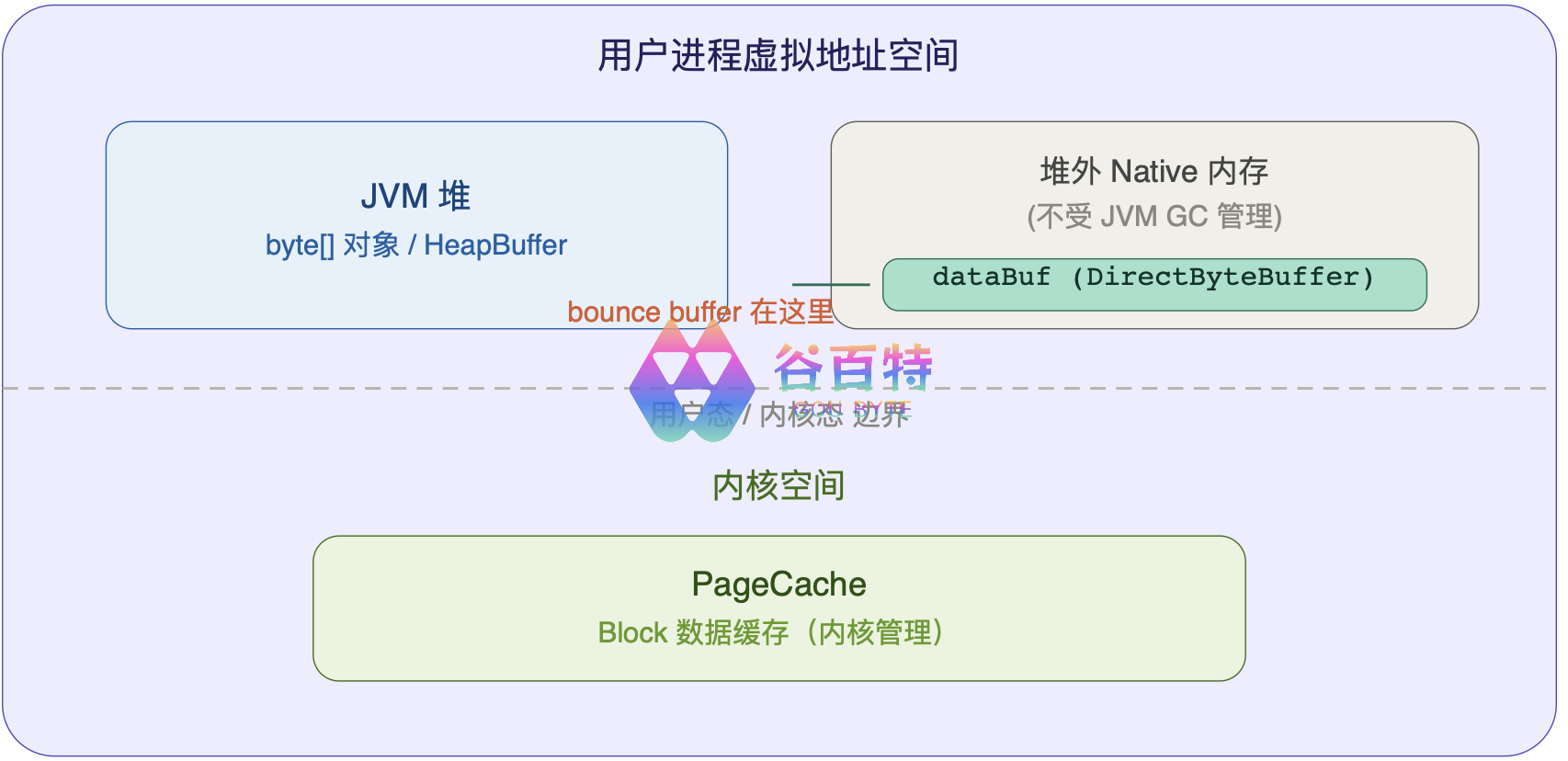
选 DirectByteBuffer 而不是堆内 byte[] 的原因:JVM 做 I/O 时,堆内 byte[] 可能被 GC 移动,需要先 pin(钉住)或隐式拷贝到 native 缓冲区。DirectByteBuffer 天然避免了这个问题。
5.3.2 数据流:2 次 CPU 拷贝

| 步骤 | 从 | 到 | 方式 | 位于 |
|---|---|---|---|---|
| ① | 内核 PageCache | bounce buffer | FileInputStream.read() / pread() | 内核 → 用户空间 native |
| ② | bounce buffer | 用户传入的缓冲区 | ByteBuffer.get() / ByteBuffer.put() | 用户空间 native → JVM 堆/用户 buf |
与传统的 TCP 远程读(4 次拷贝)相比,短路 bounce buffer 已经省掉了内核 Socket 缓冲区的 2 次拷贝。但这不叫零拷贝,只是"短路"——数据还是要经过用户空间手递手转交一次。
5.4 真正的零拷贝:HDFS Zero-Copy Read(mmap)
BlockReaderLocal.read() 的两个分支都不是真正的零拷贝。
Hadoop 2.6+ 提供了另一条路径——通过 mmap 实现真正的零拷贝,走的是 DFSInputStream 的 HasEnhancedByteBufferAccess 接口:
// DFSInputStream.java — read(pool, maxLen, opts) 完整实现
// 这才是真实代码,下面两个方法共同完成零拷贝读
// ===== 方法一:对外入口 =====
@Override
public synchronized ByteBuffer read(ByteBufferPool bufferPool,
int maxLength, EnumSet<ReadOption> opts)
throws IOException, UnsupportedOperationException {
// 确保当前有可用的 blockReader
if ((blockReader == null) || (blockEnd == -1)) {
if (pos >= getFileLength()) return null;
if ((!seekToBlockSource(pos)) || (blockReader == null))
throw new IOException(...);
}
ByteBuffer buffer = null;
// ① 先尝试 mmap 零拷贝(受 dfs.client.mmap.enabled 控制)
if (dfsClient.getConf()
.getShortCircuitConf().isShortCircuitMmapEnabled()) {
buffer = tryReadZeroCopy(maxLength, opts); // ← 真正调 getClientMmap() 的地方
}
// ② mmap 成功,直接返回
if (buffer != null) {
return buffer; // ← 零拷贝路径,buffer 直接映射 PageCache
}
// ③ mmap 不可用或不支持,退回普通短路读(bounce buffer,2次拷贝)
buffer = ByteBufferUtil.fallbackRead(this, bufferPool, maxLength);
if (buffer != null) {
getExtendedReadBuffers().put(buffer, bufferPool);
}
return buffer;
}
// ===== 方法二:零拷贝的实际执行者 =====
private synchronized ByteBuffer tryReadZeroCopy(
int maxLength, EnumSet<ReadOption> opts) throws IOException {
final long curPos = pos;
final long blockPos = curPos
- currentLocatedBlock.getStartOffset(); // ← block 内偏移
// 截断到 block 末尾,防止越界
long length63 = (curPos + maxLength <= blockEnd + 1)
? maxLength
: (blockEnd - curPos + 1);
if (length63 <= 0) return null;
// MappedByteBuffer 上限 2GB(31-bit),超出的部分本次不 mmap
int length;
if (blockPos + length63 <= Integer.MAX_VALUE)
length = (int) length63;
else
return null;
// ★ 真正发起 mmap 的地方
final ClientMmap clientMmap = blockReader.getClientMmap(opts);
if (clientMmap == null) return null; // 走普通短路读(bounce buffer,2次拷贝)
...
}
5.4.1 BlockReaderLocal.getClientMmap() — mmap 的底层入口
tryReadZeroCopy() 真正调 getClientMmap(),而这个方法在 BlockReaderLocal 的实现是:
// BlockReaderLocal.java 第 677 行
@Override
public ClientMmap getClientMmap(EnumSet<ReadOption> opts) {
// 需要校验 checksum 且没传 SKIP_CHECKSUMS 时,必须先 anchoring
boolean anchor = verifyChecksum
&& !opts.contains(ReadOption.SKIP_CHECKSUMS);
if (anchor) {
if (!createNoChecksumContext()) {
return null; // 无法 anchoring(block 未 mlock),放弃 mmap
}
}
ClientMmap clientMmap = null;
try {
clientMmap = replica.getOrCreateClientMmap(anchor);
// ↑ 最终走到 FileChannel.map(POSIX_MMAP, offset, length)
// → MappedByteBuffer(真正的零拷贝!)
} finally {
if (clientMmap == null && anchor) {
releaseNoChecksumContext(); // 失败回滚
}
}
return clientMmap;
}
只有 BlockReaderLocal 实现了 getClientMmap()。 如果当前是远程 BlockReaderRemote,该方法返回 null,tryReadZeroCopy() 直接失败退回 bounce buffer。
5.4.2 dfs.client.mmap.enabled — 零拷贝总开关
tryReadZeroCopy() 是否被调用,受一个总开关控制:
// 唯一生效位置:DFSInputStream.read(pool, maxLen, opts)
if (dfsClient.getConf()
.getShortCircuitConf().isShortCircuitMmapEnabled()) {
buffer = tryReadZeroCopy(maxLength, opts);
}
| 参数 | 默认值 | 作用 |
|---|---|---|
dfs.client.mmap.enabled | true | 总开关,控制是否尝试 mmap |
dfs.client.mmap.cache.size | 256 | mmap 映射的 LRU 缓存条目数 |
dfs.client.mmap.cache.timeout.ms | 60000 | 缓存条目过期时间 |
dfs.client.mmap.retry.timeout.ms | 300000 | mmap 失败后的重试间隔 |
设为 false 时,所有调用方的零拷贝尝试都被跳过,直接 fallback 到 ByteBufferUtil.fallbackRead() → readWithBounceBuffer()。
5.4.3 tryReadZeroCopy vs readWithoutBounceBuffer:别混淆
两者名字都带"Zero/WithoutBuffer",但本质完全不同:
| 维度 | tryReadZeroCopy() | readWithoutBounceBuffer() |
|---|---|---|
| 所在类 | DFSInputStream | BlockReaderLocal |
| 触发入口 | read(pool, maxLen, opts) | read(ByteBuffer) / read(byte[]) 内部 |
| 底层机制 | mmap → MappedByteBuffer | pread() 直接读入用户 buffer |
| CPU 拷贝 | 0 次 | 1 次(省掉 bounce,但不是零) |
| 生产可用性 | ✅ mmap 可用时自动触发 | ❌ 需 bytesPerChecksum==0(几乎不会触发) |
| 互相关系 | 完全独立,无调用关系 | 完全独立,无调用关系 |
5.4.4 mmap 为什么是真正的零拷贝:页表共享原理
这不是修辞手法,而是物理页框级别的共享——用户空间的虚拟地址和内核空间的虚拟地址,通过各自的页表,指向同一个物理页框。
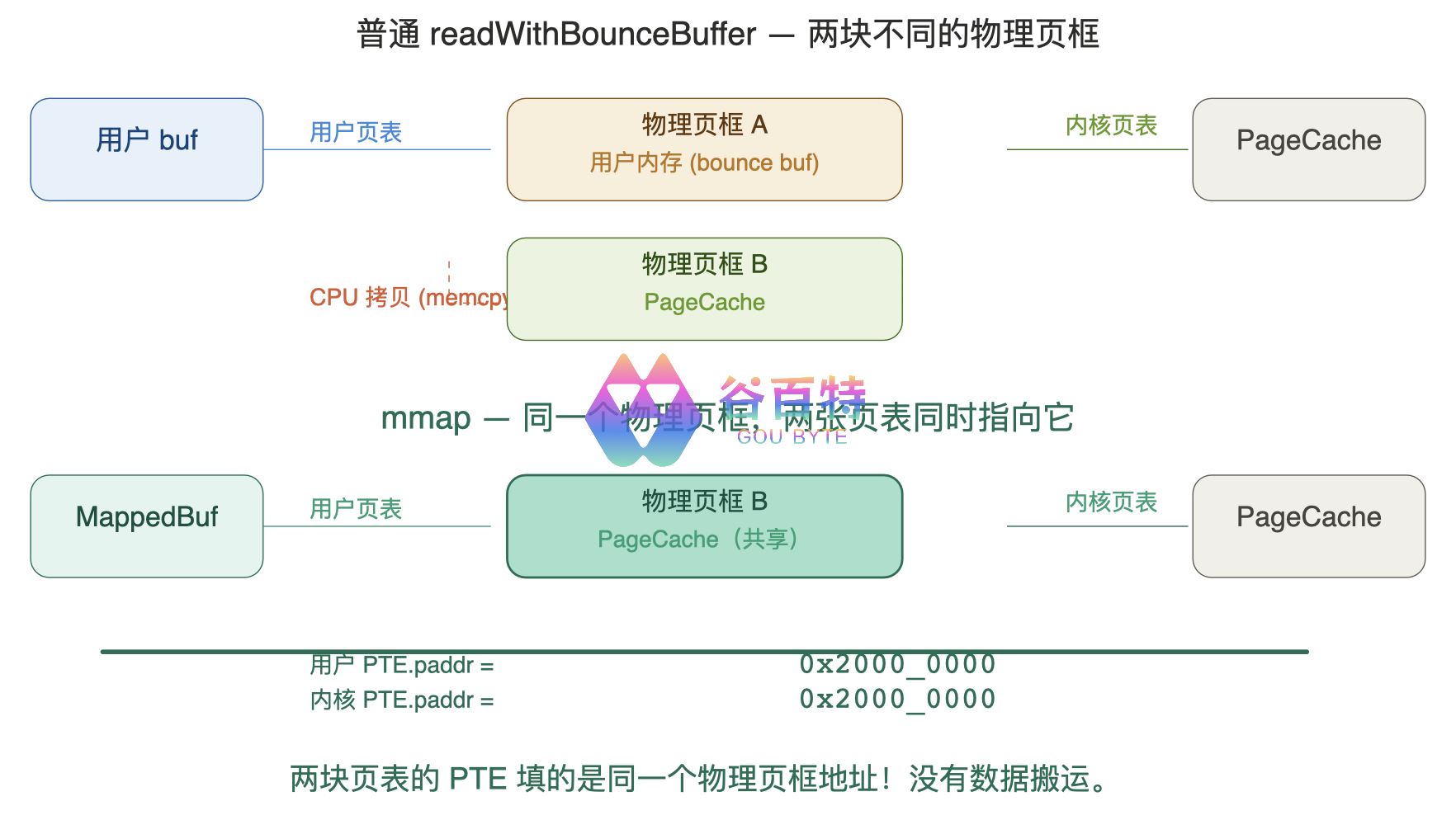
更深一层:数据是惰性加载的——缺页中断机制:
① FileChannel.map() 执行后
用户页表项全部为空(Present=0),未分配物理页框
此时 "映射" 只是一个 VMA(虚拟内存区域)记录
② 用户第一次读 MappedByteBuffer.get()
CPU 查页表 → Present=0 → 触发 Page Fault(缺页中断)
│
▼
内核缺页处理程序:
1. 分配一块物理页框(4KB)
2. 通过 DMA 从磁盘读 Block 数据到该页框
3. 填写用户页表:PTE.paddr = 页框地址, Present=1
4. 同时填写内核 PageCache 映射
5. iret 返回用户态,CPU 重试刚才的指令
6. 这次页表命中 → 数据已在内存 → 零拷贝读到!
③ 后续读同一页 → MMU 硬件直接转译
整个过程:用户态执行一条 mov 指令读取内存
没有 read() 系统调用,没有内核态切换,没有拷贝!
5.4.5 为什么不是所有短路读都用 mmap?
mmap 这条路径有严格的约束条件:
| 限制 | 说明 |
|---|---|
| 必须跳过 checksum | mmap 返回的 buffer 直接暴露内核内存,无法逐 chunk 校验。如果传入 SKIP_CHECKSUMS,getClientMmap() 内部还需要 anchoring(mlock 防止 DN 删除文件) |
| MappedByteBuffer 2GB 限制 | Java 用 int 索引,单段 mmap 不能超过 31-bit 范围(HDFS-5101) |
| 文件描述符消耗 | 每个 mmap 映射消耗一个 FD + VMA,所以需要 ShortCircuitCache 做 LRU 淘汰 |
| 并发安全 | 需要 anchoring 机制阻止 DN 在客户端读取期间删除对应 block 文件 |
bounce buffer 的最大存在理由:checksum 校验不可分割。 校验时需要一个独立的工作区,不能直接操作用户缓冲区——万一校验失败,用户缓冲区已经被污染了。
5.4.6 完整调用链总结
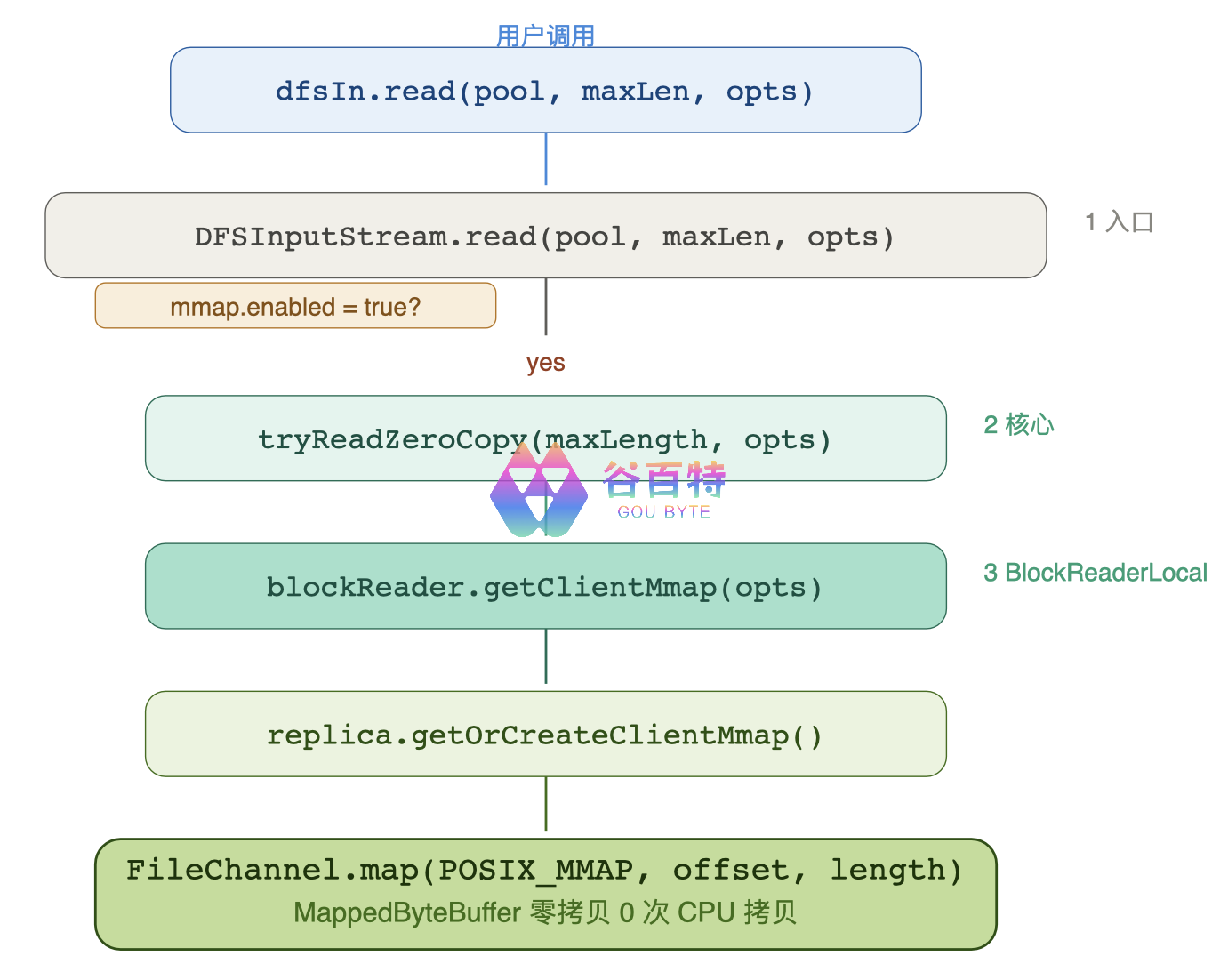
mmap 的触发条件回顾:
1. dfs.client.read.shortcircuit=true
2. dfs.client.mmap.enabled=true(默认)
3. BlockReader 是 BlockReaderLocal(短路读已生效)
4. Replica 支持 mmap(数据在本地文件系统)
5. 用户通过 DFSInputStream.read(pool, maxLen, opts) 调用
→ 普通 FSDataInputStream.read(byte[]) / read(ByteBuffer) 不走 mmap!
5.5 三种 DFSInputStream.read() 与新版短路读的关系
客户端收到 FD 后,走新版短路读——但最终执行哪个读取方法,取决于调用方用的是哪种 read() 接口。
5.5.1 三种读方法的调用链
DFSInputStream
│
├── read(byte[] buf, int off, int len)
│ │
│ └── ByteArrayStrategy
│ │
│ └── readWithStrategy() ← 统一调度引擎
│ │
│ ├── blockSeekTo()
│ │ └── BlockReaderFactory.build()
│ │ └── getBlockReaderLocal() ✅ 新版短路
│ │
│ └── BlockReaderLocal.read(byte[], int, int)
│ │
│ └── readWithBounceBuffer() ← 2 次 CPU 拷贝
│
├── read(ByteBuffer buf)
│ │
│ └── ByteBufferStrategy
│ │
│ └── readWithStrategy() ← 同一个引擎!
│ │
│ ├── blockSeekTo()
│ │ └── BlockReaderFactory.build()
│ │ └── getBlockReaderLocal() ✅ 新版短路
│ │
│ └── BlockReaderLocal.read(ByteBuffer)
│ │
│ └── readWithBounceBuffer() ← 2 次 CPU 拷贝
│
└── read(ByteBufferPool pool, int maxLen,
EnumSet<ReadOption> opts)
│
└── seekToBlockSource()
│
└── BlockReaderFactory.build()
└── getBlockReaderLocal() ✅ 新版短路
│
├── tryReadZeroCopy()
│ └── getClientMmap() ← 0 次拷贝 ✅
│
└── fallback: ByteBufferUtil.fallbackRead()
└── DFSInputStream.read(ByteBuffer) ← 退回 2 次拷贝
5.5.2 三种方法的本质差异
| 维度 | read(byte[]) | read(ByteBuffer) | read(pool, maxLen, opts) |
|---|---|---|---|
| 接口来源 | java.io.InputStream | ByteBufferReadable(Hadoop 扩展) | HasEnhancedByteBufferAccess(Hadoop 扩展) |
| 缓冲区来源 | 调用者提供的 byte[] | 调用者提供的 ByteBuffer | ByteBufferPool 借出的 ByteBuffer |
| 调度引擎 | readWithStrategy() | readWithStrategy() | 独立调度 |
| 最终执行方法 | read(byte[], int, int) | read(ByteBuffer) | getClientMmap() → mmap |
| CPU 拷贝次数 | 2 次 | 2 次 | 0 次 |
| 典型使用者 | hadoop fs -cat、MapReduce | HBase、Netty 等 NIO 框架 | Impala、Presto 等 MPP 引擎 |
5.5.3 设计哲学
三个方法体现了 "兼容层 → 扩展层 → 性能层" 的递进设计:
read(byte[]):兼容标准java.io.InputStream,让任何使用传统 IO 的框架无缝接入read(ByteBuffer):拥抱 Java NIO,让 NIO 框架减少一次byte[] ↔ ByteBuffer转换read(pool, maxLen, opts):为追求极致性能的 MPP 引擎开辟专用零拷贝通道
三种方法共享同一个 BlockReaderFactory——无论走哪条路,获取 BlockReader 时都经过:

所以新版短路读取并不是绑定到某个特定 read() 方法上,而是一种 BlockReader 获取策略。拿到 BlockReaderLocal 后,read(byte[]) 和 read(ByteBuffer) 走 readWithBounceBuffer(),read(pool, maxLen, opts) 走 tryReadZeroCopy() → getClientMmap()。
一句话:绝大多数 HDFS 客户端的短路读最终执行的是
BlockReaderLocal.read(byte[], int, int)→readWithBounceBuffer()(2 次拷贝),因为hadoop fs、MapReduce、Spark 等生态都通过标准InputStream.read(byte[])接口读取。零拷贝getClientMmap()是 MPP 引擎的高速专用道。
六、两种实现的全面对比
| 维度 | getLegacyBlockReaderLocal() | getBlockReaderLocal() |
|---|---|---|
| JIRA | HDFS-2246 | HDFS-347 |
| FD 获取方式 | RPC 获取路径 → new FileInputStream(path) | Domain Socket + SCM_RIGHTS FD 传递 |
| 权限要求 | 客户端需加入 dfs.block.local-path-access.user | 无(DataNode 代为打开 FD) |
| 安全性 | 低(绕过 DataNode 访问控制) | 高(DataNode 验证 Token 后才传递 FD) |
| mmap 支持 | 不支持 | 支持(通过 ShortCircuitReplica.loadMmapInternal()) |
| 缓存机制 | LocalDatanodeInfo(LRU 10000) | ShortCircuitCache(引用计数 + Waitable) |
| 引用计数 | 无(每次 new FileInputStream) | 有(refCount,支撑 evictable 管理) |
| 配置开关 | dfs.client.use.legacy.blockreader.local=true | 同上 =false(默认) |
| 推荐程度 | 已废弃(仅兼容旧版) | ✅ 生产推荐 |
七、实战:生产环境配置建议
7.1 推荐配置(hdfs-site.xml)
<!-- 启用短路本地读取 -->
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<!-- 使用新版 fd 传递机制(默认即 false,显式写出更清晰) -->
<property>
<name>dfs.client.use.legacy.blockreader.local</name>
<value>false</value>
</property>
<!-- Domain Socket 路径模板 -->
<property>
<name>dfs.domain.socket.path</name>
<value>/var/lib/hadoop-hdfs/dn._PORT</value>
</property>
<!-- 跳过 checksum(当 checksum 已由底层存储保证时,可选) -->
<property>
<name>dfs.client.read.shortcircuit.skip.checksum</name>
<value>false</value>
</property>
<!-- ShortCircuitCache 配置 -->
<property>
<name>dfs.client.read.shortcircuit.streams.cache.size</name>
<value>4096</value> <!-- 默认 256,大内存机器可调大 -->
</property>
<!-- mmap 零拷贝相关 -->
<property>
<name>dfs.client.mmap.enabled</name>
<value>true</value> <!-- 总开关:是否尝试 mmap 零拷贝,默认已开启 -->
</property>
<property>
<name>dfs.client.mmap.cache.size</name>
<value>256</value> <!-- mmap 映射 LRU 缓存条目数 -->
</property>
<property>
<name>dfs.client.mmap.cache.timeout.ms</name>
<value>60000</value> <!-- mmap 缓存过期时间,默认 1 分钟 -->
</property>
7.2 踩坑记录
-
Domain Socket 路径权限问题:DataNode 需要对该路径有读写权限,且客户端需要执行权限(才能 connect)。建议将 Socket 文件放在
/var/run/hadoop-hdfs/下,并由hdfs用户拥有。 -
Native 库未加载:
libhadoop.so未正确加载时,Domain Socket 不可用,会自动降级为 TCP 读取。检查:hadoop checknative -a -
mmap 零拷贝不生效:确保调用方使用
DFSInputStream.read(ByteBufferPool, maxLen, opts)接口而非标准InputStream.read(byte[])。hadoop fs -cat和 MapReduce 默认走的都是标准接口,零拷贝只在 MPP 引擎(Impala、Presto)中生效。 -
注意 mmap 的 FD 消耗:每个 mmap 映射消耗一个文件描述符。
dfs.client.mmap.cache.size=256意味着最多同时持有 256 个 mmap 映射。高并发场景下可适当增大,但要确保ulimit -n足够大。 -
mmap 导致虚拟内存耗尽:大量使用 mmap 时,注意
vm.max_map_count设置(sysctl vm.max_map_count,建议 ≥ 655300)。
八、总结
getLegacyBlockReaderLocal() 和 getBlockReaderLocal() 代表了 HDFS 短路本地读取的两个时代:
-
Legacy 路径(HDFS-2246)简单直接——RPC 拿路径,直接
open()。但权限管理复杂,安全性弱,已不建议在新集群中使用。 -
新版路径(HDFS-347)通过 Unix Domain Socket 的
SCM_RIGHTS机制实现 FD 传递,巧妙地让 DataNode 保持了对读取的控制权,同时让客户端获得了直接读取的能力。 -
真正的零拷贝:
BlockReaderLocal.read()的两个分支都不是零拷贝。readWithBounceBuffer()是默认路径(2 次 CPU 拷贝),bounce buffer 位于用户空间堆外 native 内存(DirectByteBuffer)。readWithoutBounceBuffer()在生产中几乎不触发(需要dfs.checksum.type=NULL)。真正的零拷贝方案是 HDFS Zero-Copy Read(DFSInputStream.read(pool, maxLen, opts)+ mmap +getClientMmap()),通过页表共享让用户虚拟地址和内核 PageCache 指向同一块物理页框,CPU 拷贝次数为 0。 -
三种读取接口的定位:
read(byte[])兼容标准 IO、read(ByteBuffer)拥抱 NIO、read(pool, maxLen, opts)为 MPP 引擎留高速专用道。三者共享同一个BlockReaderFactory获取 BlockReader,但最终执行的读取方法不同——前两者走readWithBounceBuffer(),后者走getClientMmap()mmap 零拷贝。
设计哲学:真正的性能优化,不是堆砌新特性,而是让数据走最短的路径——让内核做它最擅长的事(Page Cache 管理、SCM_RIGHTS FD 传递、mmap 页表映射),让用户态代码保持简单而强大。
评论区